
|
As our ability to generate, store and transmit computer based data increases, our capacity to effectively organise (structure), retrieve and utilise this information becomes more problematic. New and better methods must be developed to structure this vast information base. The authors present a formal reference model for hypermedia authoring which may be used as a basis to address the concerns expressed. This model is premised upon concept maps being logically equivalent to the associative link system. This work provides a method which may be used to guide the hypermedia author's structuring process.
Enormous efforts has been placed on the development of new technologies to physically manage the collection, storage and dissemination of electronic based data. These advances now allow vast libraries of information to be electronically stored and indexed. Workstations exist which allow easy access to computerised information, and international networks of interacting users are commonplace (Flanagan 95, Whole Earth Catalog 95, EFF 95). While there are still many purely technical problems to solve, there appears to be no essential barriers in bringing information to large numbers of users in a presentable way, allowing them to manipulate it, and allowing them to make contributions to the overall collection (Reynolds 89).
The migration of information from a paper based medium to a computer based delivery system requires the restructuring of the information. The understanding and management of this process has made little progress since the inception of the hypermedia concept in 1945.
If "the value of information lies in how it is organised"(Berk 91) is true, then new and better methods must be developed to structure this vast information base if it is to be of any value to people. Further, in order for such systems to be economically viable it is necessary to find more cost effective techniques for authoring the network of associative links.
In particular, what are the construction rules for the "hyper" portion of hypermedia? Rules of composition must be developed to guide associative link creation during hypermedia title production. Reviews of many recently published multimedia titles have shown their hypermedia link systems to be shallow, and/or incomplete and on occasion inaccurate (Bernstein 90). Link construction principles, metric systems and measurement methodologies are required to analyse the accuracy and effectiveness of the associative link system within a multimedia titles.
This paper will look at the issues associated with the structuring and retrieval of hypermedia information, specifically, the development of associative links systems which are the heart of hypermedia titles. Can we develop "rules of composition" to guide the hypermedia author's structuring process?
The authors herein present the research being done, namely the development of a formal reference model for hypermedia authoring. The paper postulates that concept maps are logically equivalent to the associative link system contained within hypermedia systems. The use of the concept model formalism provides the potential for rigorously measuring important quality attributes of a link system.
The author must work with two forms of structure, the logical structure of the information, and the physical structure of the storage/presentation system. The physical structure is tightly bound to the hardware and software system which is used to deliver the information. Issues such as layout, typography, user input devices, screen size and colour capability are just a few of the considerations an author must take into consideration when designing a hypermedia system. The logical structure is driven by the information contained within the hypermedia database, the purpose of the system and the nature of the user community.
Shneiderman, Kreitzberg and Berk stated the "Golden Rules of Hypertext" (Shneiderman 91) to be
The process of authoring this associative graph is currently very problematic. We lack the models, methodology and tools to assure proper informational design and development of hypermedia titles. "without such design guidelines and tools the ever growing network of interlinked applications is becoming increasingly spaghetti like and hard to maintain" (Bieber 95). Specifically what rules or principles of design should be followed in order to create an effective link system?
The authoring process consists of creating "meaningful" nodes, anchors and links (Garzotto 91). Links are organised into structures.
There are three basic classes of links: structural, associative (Frisse 88) and application specific. The structural links bind nodes together replicating the structure of the original media. These type of links are sometimes referred to as an objective link (Kahn 89). They represent the explicit structure of the original material.
Associative links bind nodes together based on semantic or pragmatic relationships. They are added to the title during the authoring process as the author perceives associations between ideas represent in nodes. These links are sometimes called subjective links because they are based upon the subjective understanding of the information by the author (Kahn 89).
The third class of link is the application specific link. Although this type of link can also be structural or associative, there are times when an application specific link is not one of these. For example, the author may be engaged in the development of a hypermedia title for instructional purposes. He/she may wish to create a link between a set of nodes that originally came from different references. Therefore these nodes are not originally structurally related. In addition, the content of the nodes to be linked are not semantically or pragmatically similar. The link may be used as a means of transitioning between two different concepts within a lesson plan. Since the nodes are not semantically related, this link does not qualify as an associative link but rather as a link developed to implement an instructional path through the information space. This type of link is application specific. If this hypermedia database was to he used for another purpose, this link would not necessarily exist.
Another example would be a link between two WWW nodes; one dealing with the mating habits of the Tasmanian Devil and anvil sales in Arkansas, USA. They might be linked together because the web author was listing his hobby interests. The link does not reflect either a structural similarity because the origination of the information comes from disparate sources, and it would be extremely difficult to discern an associative relationship between these two concepts. The motivation for linking originates from the user needs, an application requirement.
There are a number of hypermedia models that identified other link types. These typically are application specific type links (Parunak 91, Trigg 83, Bornstein 90, Furuta 90, Lange 90). The study of discourse grammar deals with the definition of kinds of relationships and types of links that can exist between nodes (Beekinan 74, Beekman 81, Grimes 75, Longacre 76, Longacre 80, Mann 87).
The second use of linear structures is the trail (Bush 45) or Guide Path or Guided Tour (Trigg 88). These provide a selected sequential passage through the hypermedia title's link structure. These trails are application specific, commonly used for educational purposes. The author creates an explicit path through the information space in order to convey concepts in a sequential manner.
Some hypermedia presentation systems impose linearity on the information base; the author has no choice. HyperCard is one such system. Nodes (or cards) are ordered in a linear stack.
Many common problems lend themselves to a grid structure (Rauscher 92). Matrix structures can also be developed for application specific purposes. Commercial multimedia kiosks and educational systems commonly utilise this structure.
Structural links can be hierarchical in nature as when they are used to bind entries within a book's table of content or index to the chunks of data these entries refer to. Chapters can be connected to sections within the chapter through the use of structural links.
Hierarchical links can be used to establish semantic or pragmatic relationships between two bits of information in disparate references. For example, hierarchical links can be used to link from anchor points within a map of Australia in an atlas to individual maps of the states and territories. Links can be developed connecting each state map to encyclopedic entries for cities and regions within their geographical boundaries.
Hierarchical links can be used for application specific purposes also. Once again, application specific hierarchical links can be generated by the hypermedia author or instructional designer for instructional purposes.
The advantage of hierarchical structures are that readers are already familiar with them (Brochmann 89).
Except when associative links already exist and are explicitly noted, such as cross references in the source material, it is extremely difficult to identify associative relationships through structural cues. Format is not meaning. The development of associations or semantic and pragmatic links requires a method for understanding the meaning of the data.
It is because of the extreme difficulty of content analysis, that most of the research in hypermedia authoring concentrates on the automatic identification of structural linear links during the conversion of existing information into a hypermedia structure. It is felt that the identification of these structural links is a tractable problem and thus provide immediate benefits to commercial authors.
Most attempts at developing associative link systems are hand crafted. This is because of the requirement for understanding the material requires human intellect. There have been attempts to augment this hand crafted method with computer based tools (Robertson 94). It is understood that this assistance can only provide rudimentary help and the suggestions will not always be correct. But, some help is better than none. Some of the more promising and interesting efforts in this direction are (Bernstein 90, Clitherow 89, Lenat 86, Lenat 89, Hayes 89, Yankelovich 85, Conklin 87, Marchionini 88).
Although all these works have made important inroads into the understanding of hypermedia authoring methodologies, they have not resulted in the breakthrough necessary to ameliorate the prohibitive cost constraints facing commercial hypermedia title developers. More work must he conducted to establish more viable authoring techniques. New design methodologies must be developed. We found no strong theories, or all embracing models, to help solve the problems of hypermedia authoring. Nor did we find an adequate design methodology. For this reason we are looking at the use of concept maps as a model for the hypermedia design process.
The resulting diagram is a pictorial representation of the information space, displaying all the ideas as points in a multi-dimensional space and showing how these ideas are related to each other. Distance between points or ideas in the map represent the similarity or dissimilarity between the ideas. Multi dimensional scaling algorithms are use to derive this distance. The statements are then organised into groups using a clustering algorithm.
There are a number of ways to conduct a concept mapping exercise. We have chosen a method developed by William Trochim (Trochim 89). Other approaches have been developed by (Novak 84) and (Rico 83).
The technique developed at UTS is an adaptation and extension on the concept mapping methodology developed by William Trochim (Trochim 89). Our technique is heavily based on Trochim, but for different ends. Our process has four stages.
The experts are also given a list of all the statements derived in stage one. Each participant is asked to rank the importance of each statement according to some scale. This is also done individually, without consultation.
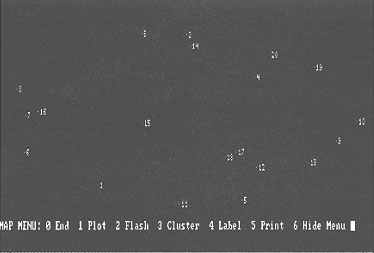
Figure 1: Map of concepts
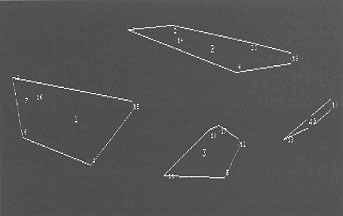
Figure 2: Clusters of concepts
At this point the information has been organised into a three level hierarchy (see Figure 3).
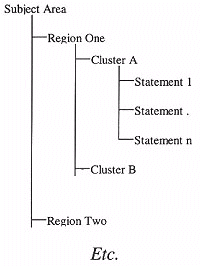
Figure 3: Hierarchical conceptual structure
This hierarchical index of the information contained within the information space can be integrated into the hypermedia title. By linking from each leaf or statement in the index to occurrences of that concept (as identified by the subject experts in stage one), the reader can utilise the index to reach all important instances of a concept. We refer to the destination point of the links from an hierarchical index entry to the actual media in the title as a content anchor (see Figure 4).
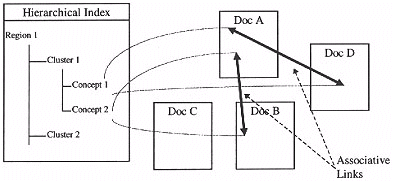
Figure 4: Associative links
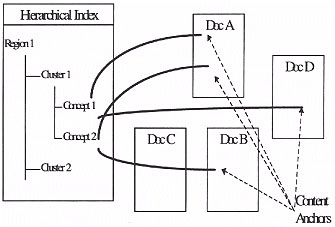
Figure 5: Hierarchical links
By following the five steps elaborated upon above, an author or set of authors can develop a rich and complete hierarchical and associative link structure over a subject domain or collection of references.
The authors were commissioned with writing an introductory tutorial for the SE Web project. The tutorial was devised based upon the focus statement, "describe the critical and practical issues in managing and improving software development in industry", using the process described in this paper to obtain the statements and named clusters. The domain experts were a group of six people who together have 23 years of industrial software development experience and 29 years of educational software development experience. One of the domain experts (also one of the authors) wrote up the web pages, which are still under construction.
Associative links were formed where statements ended belonging to two clusters, but which for syntactic reasons, ended up in one cluster. For example, one statement was "testing requires people", and there are clusters named "testing" and "people". The word "testing" comes first in the statement so it is in the "testing" cluster, with an associative link into the cluster "people". Another way of authoring this tutorial would have been to provide links into material as described in Figure 5, which would provide additional cross reference links.
Beekman, L., Callow, J. and Kopesec, M. (1974). Translating the Word of God. Grand Rapids. MI.
Beekman, L. and Callow, J. (1981). The Semantic Structure of Written Communications. Summer Institute of Linguistics.
Berk, E. and Devlin, J. (1991). Hypertext/Hypermedia Handbook, 209.
Bernstein, M. (1990). An apprentice that discovers hypertext links. In A. Rizk et al. (Eds), Hypertext: Concepts, Systems, and Applications. Cambridge University Press, Cambridge.
Bieber, M. and Isakowitz, T. (1995). Designing hypermedia applications. ACM, 38(8), 26-29.
Bornstein, J. and Riley, V. (1990). Hypertext Interchange Format: Discussion and format specification, Draft 1.3.4. Proceedings for the Hypertext Standardization Workshop. NIST Special Publication SP500-178, 39-47.
Brochmann, R. L, Horton, W. and Brock, K. (1989). From database to hypertext via electronic publishing: An information odyssey. In Barrett, Edward (Ed), The Society of Text. Cambridge MA: MIT Press, 162-205.
Bush, V. (1945). As we may think. Atlantic Monthly, 176 (July), 101-108.
Clitherow, P., Riecken, D. and Muller, M. (1989). VASAR: A system for inference and navigation in hypertext. Hypertext 89 Proceedings, ACM Baltimore, 293-304.
Conklin, J. (1987). Hypertext: An introduction and survey. IEEE Computer, 20(9), 17-41.
Davidson, D. (1989). (Unpublished interview with Emily Berk.)
EFF's (Extended) Guide to the Internet, version 2.3, Sept. 1994, URL http://www.ee.uts.edu.au/dml/local/eegtti/eegtti.html
Egan, D. E., Remde, J. R., Gomez, L. M., Landauer, T. K., Eberhardt, J. and Lochbaum, C. C. (1989). Formative design-evaluation of Superbook. ACM Transactions on Information Systems, 7(1) (January), 30-57.
Flanagan, M. (1995). Web Authoring. http://www.uts.edu.au/people/mpf/web-course/
Frisse, M. (1988). From Text To Hypertext. Byte, (October), 247-253.
Furuta, R. and Stotts, P. D. (1990). The Trellis Hypertext Reference Model. Proceedings of the Hypertext Standardization Workshop, Gaithersburg, Md, January 1990, 83-93.
Garzotto, F., Paolini, P., Schwabe, D. and Bernstein, M., (1991). Tools for designing hyperdocuments. In E. Berk and J. Devlin (Eds), Hypertext / Hypermedia Handbook, 179-224.
Glushko, R. (1989). Hypertext '89 Course Notes #3: Turning text into hypertext.
Grimes. J. E. (1975). The Thread of Discourse. The Hague.
Hardmann, L. and Sharrat, Bravo (1990). User-centered hypertext design: The application of HCI design principles and guidelines. In Hypertext State of the Market for, R. McAleese and C. Green (Eds). That Intellect, 252-259.
Hardmann, L. (1989). Evaluating the useability of the Glasgow Online Hypertext. Hypermedia Apollo 1, 1 (Spring, 1989), 34-63.
Hayes, P. and Pepper, J.(1989). Towards an integrated maintenance advisor. Hypertext '89 Proceedings, ACM, Baltimore. 1989 pp.119-127
Herrstrom, D. S. and Massey, D. G. (1989). Hypertext in context. In Barrett, E. (Ed), The Society of Text. Cambridge MA: MIT Press pp. 45-58
Kahn, P. (1989). Linking together books: Experiments in adapting published material into hypertext. Hypermedia, 1(2), 111-145.
Lange, Danny B. (1990). A formal model of hypertext. Proceedings of the Hypertext Standardization Workshop, Gaithersburg, Md., January. 145-166.
Lenat, D. B. (1986). CYC: Using common sense knowledge to overcome brittleness and knowledge acquisition bottlenecks. AI Magazine, 6.
Lenat, D. B. and Gulia, R. V. (1989). Building Large Knowledge Bases. Addison-Wesley.
Longacre, R. E. (1976). An Anatomy of Speed Notions. Lisse.
Longacre, R. E. (1980). An apparatus for the identification of paragraph types. Notes on Linguistics, 15, 5-22.
Longacre, R. E. (1989). Joseph: A Story of Divine Providence. A Text Theoretical and Textlinguistic Analysis of Genesis 37 and 19-48. Winona Lake, IN.
Mann, W. C. and Thompson, S. (1987). Rhetorical structure theory: A theory of text organization. In Livia Polanyi (Ed), Structure of Discourse. Norwood, NJ ISI Reprint Series RS-87-190.
Marchionini, G. and Shneiderman, B. (1988). Finding facts vs. browsing knowledge in hypertext systems. IEEE Computer, 21, 70-80
Martin, J. (1990). Hyperdocuments and How To Create Them. Prentice Hall, Englewood Cliffs, New Jersey (0763)2.
Nielsen, J. (1990). Hypertext and Hypermedia. Academic Press Inc. pp.1.
Nielsen, J. (1993). Useability Engineering. Academic Press.
Novak, J. D. and Gowin, B. D. (1984). Learning how to learn. Cambridge, MA: Cambridge University Press.
Parunak, H. van Dyke (1991). Tools for authoring hypertexts. In Emily Berk and Joseph Devlin (Eds), Hypertext/ Hypermedia Handbook. New York: McGraw-Hill. Chapter 20, 299-325.
Preece, J. (1994). Human-Computer Interaction. Addison-Wesley, Reading, Mass.
Qui, L. (1994). Frequency distribution of hypertext path patterns: A pragmatic approach. Information Processing and Management, 30(1), 131-140.
Rauscher, H. M., Alban, D. H. and Johnson, D. W. (1992). The Theory and Practice of Building Hypertext Systems. Unpublished draft of report.
Reynolds, C. F. and Robertson, L. (1989). Navigation requirements in large hypertext systems. Journal of Document and Text Management, 1(1), 7-23,
Rico, G. L. (1983). Writing The Natural Way: Using Right Brain Techniques To Release Your Expressive Power. Los Angeles, CA: J. P. Tarcher.
Robertson, J. and Foong, K. (1992). The hyperbase developer's toolkit. In Promaco Conventions (Ed.), Proceedings of the International Interactive Multimedia Symposium, 393-407. Perth, Western Australia, 27-31 January. Promaco Conventions. http://www.aset.org.au/confs/iims/1992/robertson.html
Robertson, J., Merkus, E. and Ginige, A. (1994). The hypermedia authoring research toolkit. Proceedings of the ECHT'94, Sept, Edinburgh, Scotland, 177-185.
Shneiderman, B. (1987). Designing the User Decades. Addison-Wesley, Reading, Mass.
Shneiderman, B., Kreitzberg, C. and Berk, E. (1991). Editing to structure a reader's experience. In E. Berk and J. Devlin (Eds), Hypertext/ Hypermedia Handbook, 143-164.
Slatin, J. M. (1991). Composing hypertext: A discussion for writing teachers. In E. Berk and J. Devlin (Eds), Hypertext/ Hypermedia Handbook, 55-64.
Smith, J. B., Weiss, S. (1989). Hypertext. Communications of the ACM, July (1988) 31(7), 816-819.
The Whole Internet Catalog, http://gnn.com/gnn/wic/index.html
Trigg, R. (1983). A network-based approach to text handling for the online scientific community. PhD dissertation, University of Maryland (University MicroFilms #8429934), College Park, Md.
Trigg, Randall (1988). Guided tours and tabletops: Tools for communicating in a hypertext environment. ACM Trans. Off. Inf Syst, 6(4), (October), 398-414.
Trochim, W. M. K. (1989). An introduction to concept mapping for planning and evaluation. Evaluation and Planning, 12, 1-16.
Yankelovich, N., Meyrowitz N. and Van Dam A. (1985). Reading and writing the electronic book. IEEE Computer, 18(10), 15-30.
| Authors: John Robertson and John Leaney School of Electrical Engineering University of Technology, Sydney Please cite as: Robertson, J. and Leaney, J. (1996). Principles of link composition for hypermedia titles. In C. McBeath and R. Atkinson (Eds), Proceedings of the Third International Interactive Multimedia Symposium, 362-370. Perth, Western Australia, 21-25 January. Promaco Conventions. http://www.aset.org.au/confs/iims/1996/ry/robertson.html |