[ IIMS 94 contents ]
An evaluation of information retrieval methods and semantic network processing for automatic link generation in hypermedia systems
C A Lindley, V R Kumar, R Irrgang, J R Robertson
CSIRO, Division of Information Technology, NSW
This paper describes a series of experiments to evaluate the effectiveness of information retrieval techniques in automatically generating links within a hypermedia system. The hypermedia system examined here is a Customer Information System developed by the New South Wales Roads and Traffic Authority. Both statistical retrieval techniques and retrieval techniques combined with semantic network processing were considered. The results of the experiments showed that statistical retrieval techniques can be very successful for automated link generation. The addition of semantic network processing provided a secondary ability to retrieve accurate information missed by purely statistical methods.
RTA information retrieval requirements
The Roads and Traffic Authority (RTA) of the New South Wales is currently addressing the need for improved Customer Service, by increasing the efficiency and effectiveness of the provision of information to the general public. One way in which this aim can be served is through the provision of a Customer Information System (CIS). A CIS Pilot Project has been developed in order to evaluate the nature and effectiveness of an information system for direct use by RTA stakeholders.
Past experience has shown that there are many problems in providing access to information in such systems. Two major difficulties are:
- structuring the information to be provided to users is extremely time consuming when carried out manually.
- limited and fixed methods of accessing the information, such as hierarchical menus, may not reflect the terms or concepts relevant to a particular user's concerns.
The research undertaken by the CSIRO Division of Information Technology and reported in this paper addresses both of these problems by the application of statistical information retrieval techniques and semantic network processing to automatic link generation in hypermedia systems.
User functions
Information browsing and search involves a range of user functions which can be identified by considering the basic information resources available within the CIS:
- informative text sources
- a hierarchical classification framework, in the form of a hierarchical index or menu
- user expressions of subjects of interest (ie, user queries).
The hierarchical index is used to access text classified under index categories, and this provides the basic functionality of the system, as shown in Figure 1.
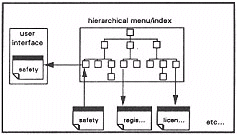
Figure 1: Current CIS functions.
These three types of information imply six additional possible ways of accessing new information from any given starting point. The access methods are:
- from an index position to further related textual material. In this case, the hierarchical index position provides a string of key words reflecting the location within the hierarchical structure.
- from an arbitrary user query to a relevant position in the hierarchical index. In this case, the user should be able to express the subject they wish to know about in unrestricted terms, avoiding the need to "second guess" a classification made by a system designer.
- from an arbitrary user query to a relevant item of text. The user's terms are mapped directly into terms within the text of logical information units, bypassing the hierarchical index. The user can sequentially browse through indicated logical text units (in order of likely relevance as defined by the system) until the required information is found (Figure 2).
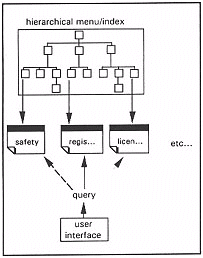
Figure 2.
- from an item of text to one or more other items of text that are relevant to the same subject. Relevance is based upon the content of the source text, and retrieved items may be ranked in order of decreasing relevance (see Figure 3).
- from an item of text to another location in the hierarchical index that is relevant to the same subject.
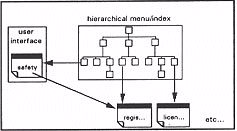
Figure 3.
- from a location in the hierarchical index to another location in the hierarchical index that is relevant to the same subject.
The effectiveness of the different methods may vary across applications. For any large system, these methods would involve a time consuming manual authoring process.
Description of project
1. Overall Aims
The aims of the evaluation described in this paper were:
- to evaluate the effectiveness of similarity based information retrieval techniques for automatically generating hypermedia links.
- to evaluate the effectiveness of similarity based information retrieval techniques for access to information based upon unconstrained user queries.
- to evaluate the effectiveness of similarity based information retrieval techniques combined with semantic network processing for query expansion, for automatically generating hypermedia links.
- to evaluate the effectiveness of similarity based information retrieval techniques combined with semantic network processing for query expansion, for access to information based upon unconstrained user queries.
2. Link Generation Experiments
2.1 Link Types and Statistical Information Retrieval
In addition to the information resources described above, a thesaurus may be used to facilitate navigation within a complex information system (in this case obtained from a separate RTA project). This means that the retrieval tasks under consideration involve the creation of links between four types, of information: user queries, a hierarchical menu/index, a thesaurus, and basic text information (Figure 4).
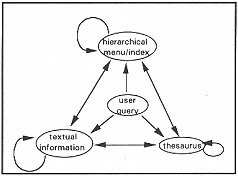
Figure 4.
All of these links can be created automatically using statistical information retrieval techniques. This requires pre-processing of the material that is to be linked. Pre-processing includes the use of.
- conflation algorithms, for word stemming to remove different word endings, variations in spelling, punctuation, and hyphenation.
- stop lists, to filter out terms which add little to the linking operation (eg, conjuncts and articles).
- synonym lists to ensure that linking is not limited to identical word forms, but captures identity of meaning.
A distinction can be made between links that can in principle be created before a user interacts with the system, and those that must be created during user interactions. In general, a priori links are those based upon known information, and include links:
- between a fixed hierarchical index and text
- between a fixed hierarchical index and a thesaurus
- between a thesaurus and text
- between elements of the hierarchical index
- between basic items of text
Links that must be created during user interaction are those that link user inputs to fixed information resources, and include links:
- between a user query and text
- between a user query and a thesaurus
- between a user query and text
There are, then, eight categories of links that can be created in the system. After the information has been pre-processed as described above, the following methods can be combined in order to automatically create the links:
- document statistics use word frequency and Ngram statistics to produce Ngram lists. Decisions on an optimal value of N for Ngrams can be made using document statistics.
- direct similarity measures are a measure of the similarity between a list of key terms and a document. Some metrics include Cosine and De Heer metrics. Other measures may be suitable for particular types of documents. Measures of homeosomy are given for a selectable number of documents most like the key term list, presented as an ordered list for both direct and indirect metrics.
- indirect similarity measures are theoretically more robust than direct measures alone, especially when used in combination with direct measures. If a text A is similar to a text B, and text C is similar to text B, then A will be found to be similar to C, even if they share no common words.
Detailed descriptions of these techniques can be found in Teufel (1989) and Teufel and Schmidt (1988).
2.2 Semantic network approaches to thesaurus processing
2.2.1 Semantic network processing: Background
In order to use the thesaurus for link generation, it can be regarded as a (very simple) type of semantic network. Methods of processing semantic networks can then be drawn upon in the design of algorithms for the information retrieval processes described above.
Quillian (1967, 1968) is generally regarded as the originator of the notion of a semantic network. The central question for Quillian was the representation format of semantic information that allowed the meanings of words to be stored in a way that facilitates language behaviour. Quillian's memory model consisted of a mass of nodes interconnected by different kinds of associative links. The nodes can each be thought of as being named by an English word. Quillian's work contributed the following concepts in semantic information processing:
- associative pathways may be traced from any particular node. The full network traced from a particular node defines the meaning of the node. The process of "tracing" the network pathways from a node is referred to by Quillian as an "activation" process.
- if pathways are traced from two original nodes, the activated pathways may intersect, indicating semantic connections between the two original nodes.
- the total link length of paths connecting two nodes represents their semantic distance.
- the activation process may begin with two root words and trace out their full concepts. If intersections occur, implicit semantic connections are revealed. There may be a very large amount of implicit and unexpected knowledge present in the network.
- activation tags accumulate to provide a context for successive inference processes. That is, activation levels within the network are a function of both the current stimuli, and the recent history of previous stimuli. The semantic connections that emerge are then a result of both current and recent stimuli.
Collins and Loftus (1975) further elaborated Quillian's initial work to suggest:
- decreasing activation levels may spread throughout the network, with a rate of reduction dependent upon the strengths of links between nodes.
- activation is released from a node at a fixed rate and depending upon how long it is stimulated.
- after stimulation ceases, activation fades over time.
- activation of an intersection must reach some threshold before it is regarded as being significant.
- activation from different sources can summate.
- the network is organised along lines of semantic similarity, ie, the more similar two concepts are the more links there will be between them. Semantic similarity is the number of links connecting two nodes, whereas semantic distance is the length of the shortest link between two components.
- links have an associated criteriality which indicates how essential a link is for a particular concept.
- a network can be primed before performing a task. Priming can be regarded as a diffuse activation of the whole network, with concentrations in different areas providing a context for subsequent inferencing.
- links may have positive and negative weightings, that can cancel out.
Further developments of semantic network processing include Anderson's ACT theory (1983). Elements of ACT theory include:
- each cognitive unit has a specific strength which increases each time it is used.
- the activation level will decay as a linear function of time since the last activation.
- retrieval rate is a negative exponential function of activation level (rather than of "semantic difference").
- there is a cut off time marking retrieval failure.
These concepts provide a variety of mechanisms that can be applied to thesaurus processing for automatic link generation.
2.2.2 Semantic network processing applied to the RTA problem
There are several ways in which semantic networks have been used to enhance text retrieval operations (see Savoy, 1992). Here the semantic network is used for query expansion, and the expanded query is passed to similarity based text retrieval routines (also used by Solvberg et al, 1991/1992).
Textual information used to explain key ideas to system users can be linked to thesaurus terms in two main ways:
- key concepts used to classify logical text units are represented within the thesaurus. In the CIS pilot project, the key concepts are the terms used to describe the components of the hierarchical index.
- thesaurus terms are linked directly to places within the body of logical text units where they are used. Eg, thesaurus terms are linked to words that are displayed within the text on CIS screens.
These two types of links within a system can then be exploited to provide access to information by any of the following six mechanisms, corresponding with the six user functions described in section 3:
- from a hierarchical index position to further related material (Figure 5). The index position provides a string of key words reflecting the location within the hierarchical index structure. The key words are represented within the thesaurus. Links between text components and the thesaurus are followed to find more information related to the key terms located elsewhere within the hierarchical structure. The thesaurus structure can be used to find information associated with closely related terms, and not just key terms themselves.
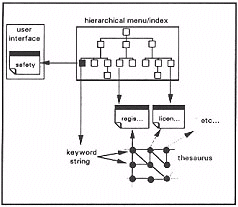
Figure 5.
- from an arbitrary user query to a relevant position in the hierarchical index. The term from the user query are mapped onto thesaurus expressions, and the linkages within the thesaurus are used to map them onto key terms within the hierarchical index. The most strongly mapped index terms are then used to take the user to the associated logical information unit.
- from an arbitrary user query to a relevant item of text (Figure 6). In this case the user's terms are mapped onto thesaurus expressions, and the linkages within the thesaurus are used to map them onto terms within the text of many logical information units, bypassing the hierarchical index. The thesaurus processing algorithm can rank logical information units in terms of anticipated relevance. The user can sequentially browse through the information.
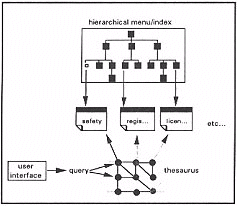
Figure 6.
- from one item of text to one or more other items of text that are relevant to the same subject. A keyword list is derived from the body of the text. Key terms are found within the thesaurus, and the thesaurus is processed to find other related text.
- from one item of text to another location in the hierarchical index relevant to the same subject.
- from one location in the hierarchical index to another location in the hierarchical index relevant to the same subject.
Methods 1. and 3. have been evaluated empirically, and the results are presented below.
2.2.3 A semantic network model for the RTA problem
Single root network model
The thesaurus is taken to be an undirected network of arbitrary connectivity. It has "nodes" and undirected "links". The thesaurus can be used to obtain a partially directed acyclic graph structure for processing as a semantic network.
Three assumptions are made, or conventions adopted, to facilitate processing:
- the level of a node is its minimum distance from a selected root node (at level 0).
- an arc is directed from the lower level node to the higher level node. Connections between two nodes at the same level are represented by a single bi-directional arc.
- beginning at the root node, activation follows the direction of the arcs in the graph.
The derived graph structure is partially directed, because arcs between nodes at the same level are bi-directional (constituting a "sibling" relationship). Every node other than the root node can only have multiple parent nodes at the same parent level. The activation of any given node from a single initial root node can then involve one of three different mechanisms:
- activation from a single parent node to a child node.
- activation from more than one parent node to a common child node.
- mutual activation between two or more sibling nodes.
These mechanisms are illustrated in Figure 7.
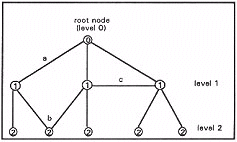
Figure 7.
[Editorial note: Figure 7 was incorrectly numbered as 8 in the original]
Spreading activation functions
Processing the network by spreading activation involves the selection of a root node. The root node is then "stimulated", ie, it has an initial activation level assigned to it. Activation then "spreads" out from this root node, in the sense that all child nodes connected to it are activated, and their activation level is a function of the activation level of the parent node and that of other child nodes that they are connected to. Activation then spreads from the child nodes to their child nodes, and the process continues recursively until the activation level along a particular path falls below a parameterised threshold. An exponential decay function is used for propagating activation from one node to another:
AL = AL + (Amax - Amin) e-DL
|
| Where: |
L is the current level within the network structure.
AL is the activation level for a node at level L.
Amin is the minimum activation level.
Amax is the maximum activation level.
D is a decay constant. |
Processing begins with AL initialised to Amin for all nodes in the network. Mechanism a. above is a simple application of this function. For activation from more than one parent (mechanism b.), the activation levels are summed. Currently, sibling activation (mechanism c.) is ignored.
The strength of the spreading activation process derives from the summation of activations from multiple stimulation points, as an indication of semantic similarity and proximity. The algorithm used in the current study involves separately generating the activated networks from each starting point individually, and then to summing the activated networks at common nodes.
2.2.4 Experiment 1
Aims
This experiment aims to evaluate the effectiveness of similarity based information retrieval techniques for:
- automatically generating hypermedia links.
- accessing information based upon unconstrained user queries.
Method
Existing text retrieval software developed by the CSIRO Division of Information Technology was adapted for this experiment. The high level algorithm used for the experiment is:
Pre-processing
- generate information traces for RTA CIS documentation.
Process
- accept user query.
- filter query to remove stop words, standard suffixes, etc.
- generate information trace for user query.
- generate similarity measures relating the query to the CIS documentation, based upon the information traces.
- return list of n most similar text items (corresponding to CIS window text content), in order of decreasing similarity.
Evaluation
In order to evaluate this approach, the tides of the RTA CIS hierarchical index entries were used as a ad of search queries. For each query, the ten most highly rated document items retrieved were noted in order. The position of the text item manually associated with the index entry in the CIS project was then compared with the list of items retrieved for that entry. This presented a measure of the precision of the retrieval technique.
Results
Results are shown on the adjacent histogram (Figure 8).
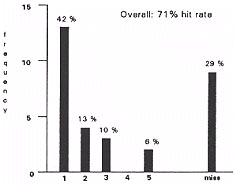
Figure 8.
2.2.5 Experiment 2
Aims
This experiment aims to evaluate the effectiveness of similarity based information retrieval techniques combined with query expansion by semantic network processing for:
- automatically generating hypermedia links.
- accessing information based upon unconstrained user queries.
Method
Text retrieval software is the same as for Experiment 1. New software was developed to parse the RTA thesaurus and process the resulting thesaurus database as a semantic network by spreading activation. The algorithm used for the experiment is:
Pre-processing:
- generate information traces for RTA CIS documentation.
- parse thesaurus files to generate Thesaurus database.
- generate information traces for RTA Thesaurus entries.
Process:
- accept user query.
- filter query to remove stop words, standard suffixes, etc.
- match query against thesaurus entries.
- process thesaurus entries using spreading activation to find semantically related terms.
- get N most highly activated thesaurus terms (values of N = 1, 3, and 5 were tested).
- get thesaurus expressions and their synonyms, and concatenate with user query to obtain an expanded query.
- generate information trace for expanded query.
- generate similarity measures relating the query to the RTA CIS documentation, based upon the information traces.
- return list of m most similar text items (corresponding to CIS window text content), ranked in order of decreasing similarity.
For step three, two methods were tried:
- using the text retrieval technique to match the query against thesaurus nodes.
- using whole word matching to match the query against thesaurus nodes.
Evaluation proceeded as for Experiment 1.
Results
- Using the text retrieval technique to match the query against thesaurus nodes.
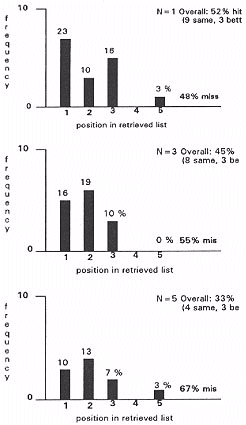
Figure 9.
- using whole word matching to match the query against thesaurus nodes.
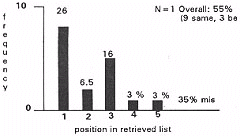
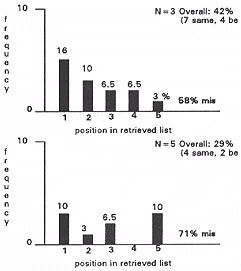
Figure 10.
Results and recommendations
The results of these experiments can be discussed in relation to the original aims:
- to evaluate the effectiveness of similarity based information retrieval techniques for automatically generating links of the type described in section 4.
An overall accuracy of 71% suggests that similarity based information retrieval techniques can have a significant impact as a substitute for manual authoring processes. In addition, informal recall testing showed that a high rate of relevant items were retrieved in addition to quantified precision measures above. In many systems, it is desirable to have more than one text item associated with any given concept, and the results of this experiment indicate that automated retrieval techniques can provide a useful and appropriate set of items for this purpose.
The relevance of the "misses" (29%) depends upon:
- how many text items can legitimately be associated with a given concept.
- the value of good but imperfect access to the correct information, in relation to the costs involved in methods of increased accuracy (eg, manual authoring).
- the availability of authors who can use the retrieval techniques as a very efficient method of reducing the search space for useful information, and can make up for the inaccuracies by a further stage of limited manual editing.
For many applications, the availability of these techniques can keep project costs within acceptable bounds.
- to evaluate the effectiveness of similarity based information retrieval techniques for access to information based upon unconstrained user queries.
Informal evaluation showed this to be very satisfactory, and provided users with the ability to explore information more quickly than by using the hierarchical menu or linear index. The large number of relevant items retrieved during a single transaction compensated users for the occasional irrelevant item.
- to evaluate the effectiveness of similarity based information retrieval techniques combined with semantic network processing for query expansion, for automatically generating hypermedia links.
- to evaluate the effectiveness of similarity based information retrieval techniques combined with semantic network processing for query expansion, for access to information based upon unconstrained user queries.
The results show that semantic networks used in a limited role for query expansion can return items more effectively than statistical similarity measures in some cases. However, overall performance was inferior due to the amplification of inaccuracies in the similarity based retrieval methods used in conjunction with semantic network processing.
Summary
In collaboration with the RTA, CSIRO has conducted a series of experiments to evaluate the effectiveness of similarity based information retrieval techniques for automatic link generation in a hypermedia system, and for access to information based upon unconstrained user queries. Query enhancement using semantic network processing was also examined. Results of these experiments show that information retrieval techniques perform well in both of these areas.
References
Anderson, J. R. (1983). A spreading activation theory of memory. Journal of Verbal Learning and Verbal Behaviour, 22, 261-295.
Collins, A. M. & Loftus, E. F. (1975). A spreading activation theory of semantic processing. Psychological Review, 82, 407-428.
Porter, M. F. (1980). An algorithm for suffix stripping. Program,14(3), 130-137.
Quillian, M. R. (1967). Word concepts: A theory and simulation of some basic semantic capabilities. Behavioural Science, 12, 410-430.
Quillian, M. R. (1968). Semantic memory. In M. Minsky, (Ed), Semantic information processing, 216-260. Cambridge, MA: MIT Press.
Savoy, J. (1992). Bayesian inference networks and spreading activation in hypertext systems. Information Processing and Management, 28(3), 389-406.
Solvberg, L., Nordbo, I. & Aamodt, A. (1991). Knowledge-based information retrieval. Future Generations Computer Systems, 7, 379-390.
Teufel, B. (1989). Informationsspuren zum numerischen und graphischen Vergleich von reduzierten naturlichsprachlichen Texten. Informatik-Dissertationen ETH Zurich NR. 13. Verlag der Fachvereine Zurich.
Teufel B. & Schmidt S. (1988). Full text retrieval based on syntactic similarities. Information Systems, 31(1).
Authors: C A Lindley, V R Kumar, R Irrgang, J R Robertson
Computer Scientists, Knowledge-Based Systems Laboratory, CSIRO Division of Information Technology, Locked Bag 17, North Ryde NSW 2113, Australia
Tel. +61-2-325-31(52,56,57) Fax. +61-2-325-3101
Email: {lindley,kumar,irrgang,robertson}@asyd.dit.csiro.au
Please cite as: Lindley, C. A., Kumar, V. R., Irrgang, R. and Robertson, J. R. (1994). An evaluation of information retrieval methods and semantic network processing for automatic link generation in hypermedia systems. In C. McBeath and R. Atkinson (Eds), Proceedings of the Second International Interactive Multimedia Symposium, 290-297. Perth, Western Australia, 23-28 January. Promaco Conventions.
http://www.aset.org.au/confs/iims/1994/km/lindley.html
|
[ IIMS 94 contents ]
[ IIMS Main ]
[ ASET home ]
This URL: http://www.aset.org.au/confs/iims/1994/km/lindley.html
© 1994 Promaco Conventions. Reproduced by permission. Last revision: 8 Feb 2004. Editor: Roger Atkinson
Previous URL 24 July 2000 to 30 Sep 2002: http://cleo.murdoch.edu.au/gen/aset/confs/iims/94/km/lindley.html
