The use of case-based reasoning in an intelligent diagnostic system for algebra
Heather Mays, Binh Pham and Andrew StranieriSchool of Information Technology and Mathematical Sciences
University of Ballarat

The use of case-based reasoning in an intelligent diagnostic system for algebraHeather Mays, Binh Pham and Andrew StranieriSchool of Information Technology and Mathematical Sciences University of Ballarat | |
During the last twenty years, computer aided learning packages have become very popular in tertiary education. However, very few packages exist which focus on diagnosing students' errors and misconceptions. Those systems which do exist are rule-based which makes adaptation difficult. When new errors are detected, new rules must be added to the system which may necessitate the rewriting or deletion of existing rules. However, one feature of case-based reasoners is their ease of adaptation particularly in domains where the knowledge is hierarchical in nature. Our research focuses on applying case-based reasoning to the creation of an intelligent diagnostic system for algebra. In this paper, we discuss the use that could be made of our diagnostic system, a justification for the use of case-based reasoning and issues which have arisen in the design and implementation of the system.
Researchers in mathematics education have shown that while there is a great diversity in the types of errors that students make, the errors are systematic and are related to the problem-solving techniques employed by students. This research has been used to guide the design process of our diagnostic system which will be based on a categorisation of problem types, solution techniques and error diagnosis which is fundamental to teaching because studying error patterns helps to reveal what has been "mis-learned" and can help the tutor to understand how students view and learn mathematics (see Farrell, 1992).
Case-based reasoning is a problem-solving paradigm which is modelled on the way that humans use past experience to solve new problems. When confronted with a new problem, the user consults memory. If problems similar to the current one have been encountered in the past, these are retrieved along with the solution. The solutions generated to the past problems can then either be reused or adapted to the new situation. For our diagnostic system, a "problem" represents an algebra error and the appropriate "solution" represents an explanation for the underlying misconception and relevant remediation.
The first prototype of the case-based reasoner was built using error data collected on a hand-written diagnostic test completed by students entering the Bachelor of Engineering program at the University of Ballarat in 1996. The prototype has been built using a traditional case-based reasoning paradigm. It includes questions and all associated errors hard-coded into the system. The final IDS will not have questions and errors hard-coded. Instead, the aim is to store templates of questions and errors that can be instantiated as required.
The remainder of this paper is divided into seven sections. Section 2 discusses the purpose of the IDS and its potential usage for students and teachers at both secondary and tertiary levels. Section 3 reviews the results of analysis of error data we performed to test the suitability of case-based reasoning for our task. Section 4 compares two of the most commonly used paradigms in Artificial Intelligence (rule-based and case-based reasoning) and provides a justification for the use of case-based reasoning in the construction of our IDS. Sections 5 and 6 discuss issues that have arisen in the design and implementation of the case-based reasoner. Section 7 outlines the future work we will undertake in producing the final case-based reasoner. The final section discusses possible extensions to the IDS and impacts that the system could have for researchers in mathematics education.
An experienced classroom teacher should be proficient in identifying and remediating student misconceptions. However, both student teachers and novice teachers lack such a bank of experience and diagnosis of errors is not typically incorporated in teacher training courses. It can take several years for teachers to acquire proficiency at diagnosing student errors and their causes. This could be expedited by using the IDS and the data it has collected.
Farrell noted that the "education of mathematics teachers is an ongoing process" which can be either formal (for example, in-service activities) or informal (for example, analysis of classroom data) (see Farrell, 1992). Farrell also noted that analysis of student responses should include analysis of correct responses, not only incorrect ones, to ensure that a correct answer is the result of correct procedures and is not merely serendipitous. Our IDS will use knowledge of incorrect solution techniques to avoid generating problems where an incorrect method will lead to the correct answer.
By using a tool such as an IDS to collect data from an entire class, the teacher will be more easily able to identify patterns exhibited by an individual student as well as those exhibited by different students. If patterns exist in the errors that students make, this may indicate significant (albeit incorrect) learning. The existence of repeated errors indicates genuine misconceptions rather than slips (see Van Lehn, 1982 or Demby, 1997). Note that this type of spontaneous mathematical behaviour is not unexpected in new learners and is often observed in more able students as they develop their own mathematical constructs (see Van Lehn, 1994 or Demby, 1997).
Typically, examples used in the classroom are deliberately simplified to help the student to focus on the main details. This means that when students are presented with more complex examples, they often fail to recognise the form of the problem and so attempt to extrapolate some previously learned technique. An IDS which is capable of presenting the student with graded problems of the same type will help the teacher to identify the student's real cause of failure to correctly solve a problem . In the case where several students (or even an entire class) produce the same incorrect solution procedure for a problem, it may indicate that there is either a flaw in the teaching of the material or that there is a natural (but incorrect) method for extrapolating a known solution technique (see Matz, 1982). This type of information can be generated by the IDS and can then be used by the teacher as a focal point of classroom discussion or to guide the feedback presented to the class. Encouraging students to explain and justify their methods can help them to identify their own flaws, thereby facilitating them in developing their own critics and checking rules. The teacher also benefits by learning more about the students and more about the art of teaching. This was well summarised by Easley and Zwoyer: "If you can both listen and accept their answers not as things to just be judged right or wrong but as pieces of information which may reveal what the child is thinking you will have taken a giant step toward becoming a master teacher rather than just a disseminator of information." (Easley and Zwoyer, 1975).
In the next section we review the results of error analysis which we undertook at the commencement of this research. The purpose of this work was to investigate the suitability of applying CBR to the creation of an IDS.
Each question and all the associated errors were hard-coded into the prototype. The prototype was then tested using error data collected from the 1998 Diagnostic Test. Our aims in testing the performance of the prototype were to determine whether we had identified most of the errors which would be made and whether the system would retrieve appropriate cases. As only one new error was discovered, it does appear that we have identified most of the common errors that tertiary entry level students make. Future testing will also involve secondary level students as we anticipate that students at different levels will employ different solution techniques and hence will make different types of errors. We also found that retrieval of appropriate error cases was better when we used inductive retrieval rather than nearest neighbour retrieval (see section 5.3). These results indicate that a CBR approach is appropriate for our IDS and we now outline how they will be used to guide the design of the revised CBR.
Advantages which have been claimed for rule-based systems include a natural means of expressing experts' problem-solving heuristics, modularity of knowledge organisation, a restricted syntax which simplifies the programming task, frequent examination of working memory which can help to direct the problem-solving process and the ability to provide an explanation for a solution by retracing the rules that were used (see Reichgelt, 1991). Many of these properties that have been claimed as advantages of rule-based systems are also cited as disadvantages (see Kolodner, 1993). In particular, the approach used for the reasoning process has been criticised because it omits knowledge about the diagnostic approach used by experts and understanding of the rules. The restricted syntax of rule-based systems also makes it difficult to represent structural knowledge, ie. knowledge about which entities are relevant in the domain. This is particularly the case where the domain is hierarchical in nature. Finally, in domains where the order of firing rules is important, updating and maintaining the system (adding or deleting rules) can be very difficult, leading to unexpected results when the new program runs.
CBR can be characterised in four stages: remind, retrieve, reuse and repair. The first stage is recalling past situations that are similar to the current one. This requires understanding of the current situation and an ability to analyse differences between past and present cases. If the current problem is identical to the past one, the previous solution could be reused. However, it is more likely that there will be some differences between the retrieved case and the current one and so some adaptation of the previous solution will be required. The new solution is then added to the case base. Cases, which can be individual or generalised, may be stored as knowledge units or split into sub-units and distributed across the knowledge base.
To represent cases, we need to identify what to store, what structure to use for description, how to organise and index the case memory and how to integrate the case memory structure into the model of general domain knowledge. We also require effective methods for searching and matching in the case base. For our IDS, the selection of the best set of cases requires identification of all errors made. Case reuse will focus on differences between past and present cases and what part of the retrieved case that can be transferred to the new one. Adaptation will involve generating complete explanations for all errors present in a student's response which will be based on causal knowledge of errors in the domain. When a new error is encountered, it will be incorporated into the existing case base along with an explanation.
All existing mathematical diagnostic systems are rule-based with questions and error libraries hard-coded into the system which makes adaptation difficult. As new errors are detected, new rules must be added to the system which may necessitate the rewriting or deletion of existing rules. Our decision to implement the IDS using case-based reasoning was determined by several factors. Firstly, adaptation is fundamental to CBR systems but is more difficult to achieve in rule-based systems. Secondly, the most important feature of our IDS will be its ability to provide explanations of errors and to target remediation appropriately. It is anticipated that this can be achieved more easily in a case-based system where an explanation field is included as part of each error case than it could be in a rule-based system. Finally, we expect that the hierarchical nature of the domain knowledge can be exploited in a case-based system to improve the efficiency of retrieval and accuracy of error diagnosis.
To extend the capability of the initial case-based reasoner in diagnosing errors, the structure of the revised system will need to take account of the hierarchical nature of the domain. To do this, we have generated a hierarchical network of algebraic skills which will be reflected in the structure of the final CBR. Part of the network corresponding to work with indices is shown in Figure 1 below. The leaf nodes of the network correspond to individual concepts. In the final CBR, the leaf nodes will also represent individual concepts but will include all associated errors. Intermediate nodes will contain other domain information, eg. branches of the network corresponding to indices and logarithms will be linked. The high-level nodes Indices and Logarithms will contain information such as the need to employ logarithms to solve indicial equations. To evaluate efficiency, a case base with redundant leaf nodes will be compared with one where each leaf node only appears once within the network. For example, a commonly reported error is to multiply coefficients when adding like terms. Because the task of adding like terms is encountered in most algebraic manipulation, we expect that including this node in a number of places throughout the case base will improve the system's efficiency.
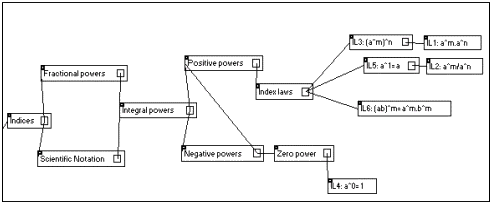
Figure 1: Part of the skills network used to design the IDS
Other mathematical diagnostic systems have also made use of the hierarchical nature of the domain knowledge. For example, the original BUGGY program was based on a procedural network in which nodes contained information about both the concepts and the method(s) for performing the procedure (see Brown and Van Lehn, 1980). The network was thus a means of modelling the different methods for performing the same skill. In DIAGNOSYS (a rule-based computer diagnostic test), the software was based upon a skills network which is a tree structure where nodes represent a single task in algebra (see Appleby et al, 1997). By combining the two approaches, we expect that our IDS will be able to determine all valid solution methods for a particular problem, identify the underlying skills needed to solve the problem and associated errors.
We began by identifying the key features to include in each case. For diagnosing errors, the most important feature of an algebra problem is the solution technique employed by the student because it determines the skills required to solve the problem and hence also determines the types of errors that the student may make. This feature can then be used to guide retrieval of relevant cases from the case library and hence was common to all cases (see section 5.3).
Similarly, all cases included fields for the student's input (as a text string), the processed answer string (see section 6.2), a Boolean field indicating whether or not the student's answer was correct and a text field to explain the student's misconceptions and associated errors. This last feature was included because one of the strengths of the IDS will be its ability not just to diagnose errors but to report and explain these. This requires the identification of the solution technique used, the skills which have not been mastered and the particular misconceptions involved. The explanation for a current case can then be generated by adapting explanations for related cases and the output can then be used to target remediation to the individual user. In the final CBR, we aim to modify the original prototype so that it will be able to generate new problems as well as all valid solution techniques and the associated errors.
In testing our prototype, we used both Nearest Neighbours and Inductive retrieval techniques. In Nearest Neighbour matching in the ReMind shell, the user creates a vector of importance values (or weights) for all the features of a case. Each feature of the input case is then compared with the corresponding feature in the stored case and a similarity score for that feature is calculated. (The method for calculating the similarity score is dependent upon the data type of that feature.) An overall measure of similarity between the two cases is then calculated as the weighted average of the feature similarity scores. The major drawback with this method is that retrieval cannot commence until a similarity score is calculated for every case within the library.
Inductive retrieval involves the clustering of related cases to improve the efficiency of retrieval. Given a set of classified cases, induction provides a means of deriving the rules which led to the classification. ReMind provides the user with the facility to build their own qualitative models of the domain knowledge to guide index generation. A qualitative model is a means of developing summaries of features as well as defining causal relationships between case features If a qualitative model is not defined, ReMind builds its own cluster tree using the CART algorithm (see Breiman et al, 1984).
For the prototype, our testing indicated that inductive retrieval was superior to nearest neighbour retrieval. Performance of the inductive retrieval process was improved by creating our own qualitative models of the domain. This was expected because of the hierarchical nature of the domain knowledge and provided further evidence that we should attempt to exploit this feature in the revised CBR. Representation of the domain knowledge in mathematics is problematic due to the symbolic nature of the notation. In the next section we discuss strategies we have adopted to overcome these problems.
Firstly, we cannot expect students to accurately represent their mathematics using strings. Rather, we need to provide an interface which allows students to input their answers in formal notation which the system will then convert to text strings. This will be facilitated by using the MathInput Dynamic Link Library (DLL) authored by John Appleby at the University of Newcastle upon Tyne as part of the ongoing Teaching and Learning Technology Programme (see Appleby et al, 1997). It provides a window for entry of algebraic expressions including powers, roots, fractions and brackets with insertion of standard functions and pi. Operation of MathInput is similar to that of the Equation Editor in MicroSoft Word. Entry may be done by typing the complete expression, by using the toolbar, by using hot-keys or by use of standard editing facilities such as cut and paste. The output is a simple string which can then be parsed. MathInput can also convert a string into mathematical notation for display on screen.
The purpose of the second stage is to reduce the complexity of an expression by eliminating the use of parentheses and operator precedence. An example of an algebraic expression is
We have addressed a number of issues which have arisen during the design of the case-based reasoning component of our IDS. In the next section we discuss some future work required before the complete IDS can be implemented.
The basic CBR approach involves storing cases in a flat memory with no organisation of the cases. Whilst this facilitates the addition of new cases to the library, it means that during the retrieval stage, the entire case library must be searched serially which becomes computationally expensive for large libraries. To improve search efficiency, several authors have proposed alternative approaches. One of these is Stratified Case-based Reasoning which involves the production of abstract solutions during hierarchical problem solving (see Branting and Aha, 1995). These abstract solutions are used to assist in retrieval, matching and adaptation of cases. In standard case-based reasoning, case representation can be very simple (using feature vectors) or complex (using semantic nets). The simpler the representation is, the lower the computational costs are but also the lower the representational power. Branting and Aha proposed the use of case abstraction as a means of reducing this complexity Their approach is based on the observation that in hierarchical problem solving, solutions can be produced at different levels of abstraction and the more abstract solutions can assist in the indexing, matching and adaptation of solutions. Such a case is called stratified and Branting and Aha define stratified CBR as the use of stratified cases.
There are a number of potential benefits associated with this approach. For indexing and retrieval, a solution at a higher level of abstraction can provide an accurate index for less abstract solutions. This makes matching less expensive than at ground-level abstraction. Similarly, adaptation of cases can be performed at the most suitable level of abstraction reducing the costs associated with adapting less abstract, non-matching case features. During searching, one task is to find an optimal (or near-optimal) route between a goal state and a starting state. To perform this task, Branting and Aha defined a set of traversal operators and for each position the set of traversal operators associated with it is determined. The solution paths found at every level of abstraction are retained. Because of the reduced field size, searching at higher levels of abstraction reduces costs. The empirical work conducted by Branting and Aha supported their hypothesis that reusing abstract case solutions decreases costs compared with reusing ground-level solutions only. Because the domain knowledge in algebra is hierarchical in nature, use of a stratified case-based system will be investigated.
Evaluation of case-based reasoners involves two measures of solution quality, viz. precision and recall. Precision is a measure of the relevance of items found and recall is a measure of the effectiveness of the retrieval mechanism which depends upon knowledge of the contents of the entire case library (see Wallis and Redding, 1996). These measures are defined as:
| precision = | number of relevant items found number of items found |
| recall = | number of relevant items found number of relevant items in the library |
In our IDS both measures of solution quality will be important in testing whether the system can correctly identify all errors that a student makes. Because knowledge of the complete contents of the final case base will probably not be known, testing of the first prototype has focused on precision and the most appropriate retrieval technique to use. For the final system, we will use evaluation to test and analyse performance of the system. The results of the evaluation will also be used to guide our search for methods for improving system performance.
Birenbaum, M., Kelly, A. E. and Tatsuoka (1993). Diagnosing Knowledge States in Algebra using the Rule-Space Model. Journal for Research in Mathematics Education, 24(5), 442-459.
Branting, L. K., & Aha, D. W. (1995). Stratified case-based reasoning: Reusing hierarchical problem solving episodes. Proceedings of the Fourteenth International Joint Conference on Artificial Intelligence. Montreal, Canada: Morgan Kaufmann. pp. 384-390.
Breiman, L., Friedman, J. H., Olshen, R. A. and Stone, C. J. (1984). Classification and Regression Trees. Wadsworth International Group: Belmont, California.
Brown, J. S. and Van Lehn, K. (1980). Repair Theory: A generative theory of bugs in procedural skills. Cognitive Science, 4, 379-426
Davis, R. B. (1984). Learning Mathematics: The Cognitive Science Approach to Mathematics Education. Croom Helm: London.
Demby, A. (1997). Algebraic Procedures used by 13-to-15-year-olds. Educational Studies in Mathematics 33, 45-70.
Easley, J. A. and Zwoyer, R. E. (1975). Teaching by listening - toward a new day in math classes. Contemporary Education, 47, 19-25.
Farrell, M. A. (1992). Learn from Your Students. The Mathematics Teacher, 85(8), 656-659.
Kolodner, J. (1993). Case-Based Reasoning. Morgan Kaufmann Publishers: San Mateo, Cal.
Matz, M. (1980). Towards a Computational Theory of Algebraic Competence. Journal of Mathematical Behaviour, 3(1-2) , 93-166.
Matz, M. (1982). Towards a process model for high school algebra. In Sleeman, D. and Brown, J. S. (eds.), Intelligent Tutoring Systems. Academic Press: London. pp. 25-50.
Mays, H., Pham, B. and Stranieri, A. (1997). Analysis and Cognitive Representation of Algebraic Errors as a Basis for an Intelligent Diagnostic System. Proceedings 4th Australasian Cognitive Science Conference (in press). Newcastle University, September 1997.
Mays, H. (1998). Construction of an Intelligent Diagnostic System in Algebra based on Case-based Reasoning and Cognitive Factors. Research Report 98/3. School of Information Technology and Mathematical Sciences, University of Ballarat.
Reichgelt, H. (1991). Knowledge Representation: An AI Perspective. Ablex Publishing Corporation: Norwood, New Jersey.
Swedosh, P. (1996). Mathematical Misconceptions Commonly Exhibited by Entering Tertiary Mathematics Students. In Clarkson, P. (ed.), Technology in Mathematics Education. Melbourne: MERGA. pp. 534-541.
Van Lehn, K. (1982). Bugs are not Enough: Empirical Studies of Bugs, impasses and Repairs in Procedural Skills. Journal of Mathematical Behaviour, 3, 3-71.
Wallis, P. and Redding, N. (1996). Assessing Recall in Information Retrieval. ACSC'96 Proceedings. Nineteenth Australasian Computer Science Conference, RMIT, Melbourne, 31 January-2 February 1996, 543-552.
| Authors: Heather Mays, Binh Pham and Andrew Stranieri School of Information Technology and Mathematical Sciences University of Ballarat PO Box 663, Ballarat, Victoria 3350, Australia Ph 03 53 279 259 Fax 03 53 279 289 h.mays@ballarat.edu.au, b.pham@ballarat.edu.au, a.stranieri@ballarat.edu.au Please cite as: Mays, H., Pham, B. and Stranieri, A. (1998). The use of case-based reasoning in an intelligent diagnostic system for algebra. In C. McBeath and R. Atkinson (Eds), Planning for Progress, Partnership and Profit. Proceedings EdTech'98. Perth: Australian Society for Educational Technology. http://www.aset.org.au/confs/edtech98/pubs/articles/mays.html |